 集中連載:DNSの仕組みと運用(1) DNSの仕組みの基本を理解しよう
|
| |
| リスト1 hostsファイルの例 |
hostsファイルは、インターネットの前身であるARPANETで生まれた、一番最初の「名前解決」サービスだ。現在でも、小規模なネットワークでは有効な方法だ。非常に単純な対照表で運用も設定も楽だが、登録されるホスト名が増えれば逆に非効率的な仕組みであることも、直感的に理解してもらえるだろう。hostsファイルは、各ホストごとに設定しなくてはならないし、そもそも各ホストで同じ名前で設定できているという保証もない。
ARPANETにおいても、ネットワークに接続されたホストが数百を超えたあたりから運用の限界に達した。そこで考案されたのがDNSであり、1984年より実際に運用が始まった。hostsファイルのような対照表を管理する専用サーバ=DNSサーバ(ネーム・サーバ)に情報を集約して、名前解決が必要なクライアントやアプリケーションから問い合わせをさせよう、という発想である。これにより、データ管理はDNSサーバだけで行えばよいことになる。だが、単にhostsファイルをそのままサーバへ移行するだけでは問題も残る。
例えば、たった1つのDNSサーバだけで全世界に存在する数百万以上のホスト情報を処理するのでは負荷に耐えられないだろうから、複数サーバによる運用は当然必要となる。だが、それらで完全に同じデータを持ち合うのでは、非常に非効率的だ。インターネットに接続する組織で、(当時は考えもしなかっただろうが)全世界に存在する数百万以上のホスト情報を保持しないといけないとしたら、これはかなりの負担だ。
また、「ホスト名のユニーク性」という問題もある。もしホスト名を付ける場合に、数百万ものホストが登録されたデータに対して、手動でユニーク性を確認しなければならないとしたらどうだろう。最も効率的なのは、ある種のホスト命名規則を用いて、ユニーク性を保証することだ。
これらを解決するのが、DNSの根本ともいえる「ドメイン・ツリー」の概念である。
■「ドメイン・ツリー」と「分散環境」
普段使用される「DNS名(ドメイン名)」などと呼ばれるホスト名は、「.(ピリオド)」でいくつかの階層に区切られる。それぞれの階層ごとに、それ以下に含まれる下位ドメイン名やホスト名を管理するという「分散型」サービスとなっている。
 |
| 図1 ドメイン・ツリーの概念 |
このツリーの「枝分かれ」部分に該当するのが、いわゆる「ドメイン」である。「atmarkit.co.jp」など、上位ドメイン名を付けたものと区別するために「ノード」などとも呼ばれる。また、このようなデータ構造を含む名前を「名前空間(ネーム・スペース:Name Space)」などとも呼ぶ。
各ノードでは、
- 自身の下位ドメイン(サブドメイン)として何があるのか。そのサブドメインの情報を持っているDNSサーバは何か
- 自身に所属するホストの情報(IPアドレスなど)
などの情報が管理される。これらを管理しているのが、それぞれのノードに位置して、そのドメインを管理するDNSサーバである。
ドメインのレベルによっては、主にサブドメイン情報のみを管理するサーバもあるかもしれないし、ホストしか管理していないサーバもあるだろう。だが、それぞれのDNSサーバの挙動や役割は、大きくは変わらない。
基本的に、各ノードに位置するDNSサーバでは、自身の管理するドメイン内情報とサブドメインのDNSサーバ名しか知らない。そこで、DNSへの問い合わせ側(DNSクライアントのことだが「リゾルバ」などとも呼ばれている)は、この階層を上位から順にたどっていけばよい。ルートからjpドメインのDNSサーバへ、jpドメインのDNSサーバはcoドメインのDNSサーバを知っているので、次にcoドメインのDNSサーバへatmarkit.co.jpドメインのDNSサーバを尋ねる。そして最終的には、「www.forum.atmarkit.co.jp」のIPアドレスを知るDNSサーバ(ここではforum.atmarkit.co.jpドメインのDNSサーバ)までたどり着けるだろう。
一見、非常に煩雑に見えるかもしれない。だがこのようにデータが配置できれば、各ノードで分散して情報を保持できるし、あるノードにおいて「host1」というホストを登録しても、ノード内のユニーク性さえ保証すれば、ドメイン名をホスト名に付加することで*1、自動的にユニーク性が保証される。実は、非常に効率的かつ柔軟なシステムなのである。すなわちDNSとは、全世界に張り巡らされた「分散協調型データベース・システム」なのだ。
また、こうした運用を行ううえで、上位ドメイン(ノード)はサブドメイン(ノード)のDNSサーバ情報のみを保持しており、そのサブドメイン以下の情報についてはまったくタッチしていない。つまり、サブドメインを完全に信頼して、サブドメイン以下の定義(さらにどのようなサブドメインが含まれるか、どのようなホストが含まれているかなど)は、そのサブドメインに任せてしまうことになる。実は、1台のDNSサーバで自身のドメインと、そのドメインのサブドメイン情報をも管理してしまうことは可能なのだが、この場合、サブドメインの情報の管理は、別のDNSサーバに任せてしまうわけだ。
なぜか? 例えば、一度組織にドメインが割り当てられてしまえば、そのドメインでどのようなサブドメインを作ろうと、ホスト名を登録しようと、完全に自由だ。ドメイン以下のことはそれぞれの組織に任せてしまった方が、管理効率は向上するからだ。これを、上位ドメインからサブドメインに対する「権限委譲(delegation)」と呼ぶ。権限委譲とは、自身から別のDNSサーバへその部分の管理権限を委譲する、という意味である。すなわち、ドメイン・ツリーは世界中の無数のDNSサーバをつなぐ「信頼の連鎖」ツリーでもあるのだ。
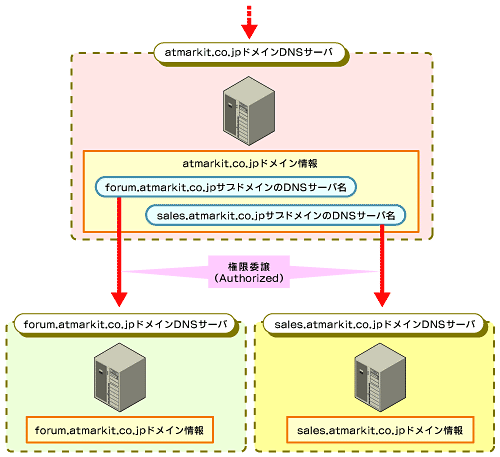 |
| 図2 権限委譲とドメインの関係 |
皆さんの組織のドメインも、必ずどこかの上位ドメインから権限委譲されている。例えば、atmarkit.co.jpドメインは、co.jpドメイン(を管理するDNSサーバ)から管理権限を委譲されている。詳しくは本連載の第2回以降で説明するが、各組織のDNSサーバをインターネット上に立ててドメイン情報を登録し、上位ドメインでそのドメインへ権限委譲していることを登録して初めて、インターネットのコミュニティから皆さんの組織のドメインとホストが、DNS上の一員であることが確認できるのである。
|
■「ゾーン」と「レコード」
では、各ノードのDNSサーバではどのような情報が必要になるのだろうか。各ノードで管理されるDNS情報の単位を「ゾーン」と呼ぶ。ゾーンは、DNS管理から見た場合のデータ範囲だ。1台のDNSサーバで複数のドメイン(親ドメインとサブドメインなど)を含む単一のゾーン情報を管理している場合もあれば、1台のDNSサーバで複数のゾーンを管理している場合もある。つまり、1つのゾーンは必ずしもドメインや物理的なDNSサーバの単位と一致するわけではないのだが*2、少しややこしいので、ここでは「“1ゾーン=1ドメイン”を1台のDNSサーバで管理している」と考えてもらっていい。
ゾーンに含まれるデータの単位が「レコード」だ。まさしく表データの中の1つ1つの行だと思っていい。ただし、データの種類は多岐にわたり、行というイメージからは程遠いかもしれない。実は、ゾーンに登録されるレコードは、ホスト名とIPアドレスの情報だけではない。以下に、主なレコードの種類を紹介する。
| ||||||||||||||||||||
| 表1 主なDNSレコードの種類(こちらをクリックすると別ウィンドウで表の全体を表示します) |
まず「SOA(Start Of a zone Of Authority)」は、ドメイン定義を宣言するレコードだ。ドメインのDNSサーバ名のほか、主にゾーン情報としてほかのDNSサーバへ転送する際の管理情報などから構成されている。ゾーン転送については連載の第3回にて解説する予定なので、いまはドメインのヘッダ情報のようなものだと考えていてほしい。
NSレコードは、ドメインとそのドメインのDNSサーバを指定するレコードだ。このレコードによって、サブドメインの存在とそのDNSサーバへの権限委譲が確認できる。
次に、Aレコードがホスト名からIPアドレスを得るためのレコードだ。例えば、WebブラウザがユーザーにURLを入力されて、そのホスト名からIPアドレスを取得する場合は、DNSサーバに対してこのAレコード情報を返答するよう命令しているのである。
Aレコードなど、ホスト名をキーにしてIPアドレスといった付随情報を取得するDNS解決方法を「正引き」と呼ぶ。逆に、IPアドレスをキーにしてホスト名を得る方法を「逆引き」と呼んでいる。逆引きのためのレコードが「PTR」レコードだ。それぞれ背中合わせの同じような処理に見えるかもしれないが、DNSにおいてはまったく別のレコードに依存している、別々の処理である。
逆引きは何のために使われるのかと思われるかもしれないが、確かにそれほど必須というべきレコードではない。使用例を挙げると、Webサーバのログに記載されているIPアドレスをホスト名へ変換する場合などだ。しかし、そうした利用を想定しないのであれば、PTRレコードをいちいち設定するのは手間なので、クライアント・マシンなどでは登録が省かれることも多い。
そのほか、MXレコードはそのドメインのメール・サーバを示す。例えば、
president_fujimura@atmarkit.co.jp
という右辺がドメインになっているメール・アドレスに対して、転送元メール・サーバ(sendmailなどのMTA)は通常、atmarkit.co.jpドメインのDNSサーバからMXレコードを検索する。
 |
| 図3 MXレコードを用いたメール転送 |
そして、MXレコードからatmarkit.co.jpドメインの受信用メール・サーバ名を取得し、そのメール・サーバに対してメールを転送する。本来、メール・アドレスの右辺はメール・サーバ名そのものだったのだが、このようにDNSとの連携によって、ドメイン名を用いることもできる。
|
■DNS検索の仕組み
では実際に、どのようにDNS解決が行われているのかを見てみよう。すでに述べたように、DNS解決はドメイン・ツリーに沿って行われる。例えば、「www.atmarkit.co.jp」というホスト名からIPアドレスの解決を行うには、最上位のjpドメインのDNSサーバに接続して、次にco.jpドメインのDNSサーバ名を知る必要がある。
だが、ちょっと待ってほしい。すでに問題が発生している。そもそもjpドメインのDNSサーバ名(またはそのIPアドレス)をどうやって知ればいいのだろうか。実をいえば、上の文章には多少ウソがある。jpドメインはドメインとしては最上位だが、DNSサーバのツリー構造においては、最上位では“ない”のだ。
もう一度、図1を見てほしい。ここの一番上に「ルート・ノード」というのがあることが分かるだろうか。つまり、トップ・レベル・ドメイン(TLD:Top Level Domain)の上位にルートと呼ばれる特別なノードが存在しているのだ。このノードの正体は「ルート・ネーム・サーバ」と呼ばれるDNSサーバだ。
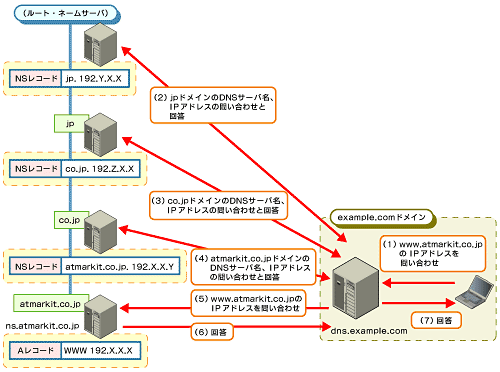 |
| 図4 DNS検索の仕組み |
ルート・ネーム・サーバは、全世界のDNS環境の最も頂点に位置するDNSサーバである。「.com」「.net」「.jp」など、最上位のトップ・レベル・ドメインのDNSサーバ情報を保持するDNSサーバだ。つまり、DNS問い合わせの「スタート・ポイント」であり、ここからすべての検索は開始される。このルート・ネーム・サーバを知らない限り、ドメイン・ツリーからの検索は不可能だ。逆にいえば、すべてのリゾルバは、このルート・ネーム・サーバの情報さえ最初に与えられれば、確実に必要とするレコードまでたどり着けることだろう。
DNS検索は、原則的にはこのルート・ネーム・サーバからまずスタートして、順に下位DNSサーバへの問い合わせを繰り返して、最終的に目的レコードまでたどり着くことになる。
■「再帰検索」と「リゾルバ」
図4で少し注意が必要なのが、図の右側に見えるDNSサーバの存在だ。これまで例として挙げてきた「atmarkit.co.jp」ドメインではないうえに、これまで説明してきた「自身のドメイン情報を提供する」DNSサーバとは位置付けが違うのを分かってもらえるだろうか。実は、このDNSサーバはリゾルバ(DNSクライアント)として動作している
例えば、「ns.atmarkit.co.jp」や上位のDNSサーバは、外部からの問い合わせに対応したり、ドメイン情報を管理するDNSサーバだ。だが、普段解決する情報は自身が管理しているゾーン情報だけで、ほかのドメインに関する問い合わせに対しては「知らない」とただ返答するだけだ。
これに対して「dns.example.com」は、ユーザーからの外部ドメインなどの情報問い合わせ要求を受け付けて、先ほど説明したようにルート・ネーム・サーバやそのほかのDNSサーバへ順に問い合わせを行い、DNS解決を最後まで行おうとする。
この違いは、実は問い合わせ方法にある。「dns.example.com」は、この例では「リカーシブ(Recursive:「再帰検索」と呼ばれる)」というタイプの問い合わせをユーザーから受け付けている。この場合、DNSサーバはDNS解決が完結するまでドメイン・ツリーをたどり、(ほかのサーバに対して)検索を行い、最終結果を返さなければならない。
一方、「ns.atmarkit.co.jp」が「dns.example.com」から受けたのは、「イテレイティブ(Iterative:「反復検索」と呼ばれる)」問い合わせだ。この場合、自身が管理しているゾーン情報にのみ返答し、ほかのサーバへ問い合わせを行うことはない。
多少ややこしいのだが、DNSサーバはこのように問い合わせ種類によって、まったく異なる動作を行う。ここでは、別サーバとして表現したが、組織によっては同一サーバで兼ねていることもある。
「dns.example.com」のように、再帰検索によって完全にDNS解決を行えるリゾルバをRFC1123では「フルサービス・リゾルバ(Full-Service Resolver)」、「dns.example.com」へ要求を送るだけのDNSクライアント(多くの場合は、皆さんが使用しているクライアントPCやメール・サーバなど)を「スタブ・リゾルバ(Stub Resolver)」と呼んで区別している。また、スタブ・リゾルバ機能だけを実装しているDNSサーバ(俗に「スレーブ・サーバ(Slave Server)」と呼ぶ*3)もある。DNS問い合わせを受け付けるが、自身では再帰検索を行わないで、別のフルサービス・リゾルバDNSサーバ(「フォワーダ」と呼ばれる)へそのまま検索を転送して、依頼をするサーバだ。社内のDNSサーバを階層的・多段的に配置したい場合などに使用されることがある。
このように、普段クライアントPCへ設定している「DNSサーバ」の項目は、多くの場合、実はマスタ・サーバではなく、フルサービス・リゾルバ用DNSサーバなのである。要するに、DNSサーバにはさまざまな機能が詰め込まれており、多様な使用方法があるということなのだが、技術書によっては、これらの違いは当然のこととして表されている場合も多い。最初は分かりにくいと思われるので、しっかりと把握して混乱しないようにしよう。
|
■「逆引き」と「逆引き用ドメイン・ツリー」
これまで説明したドメイン・ツリーによるドメイン検索は、正引き用の検索だ。つまり、SOAレコードやAレコード、MXレコードなどはこの検索経路をたどる。注意が必要なのは、逆引きのときのPTRレコード検索だ。つまり、PTRレコード検索の場合は、最初に与えられるのはIPアドレスなので、当然このようなドメイン・ツリーは検索できない。そこで逆引きのためには特別な「逆引き用ドメイン・ツリー」が用意されている。
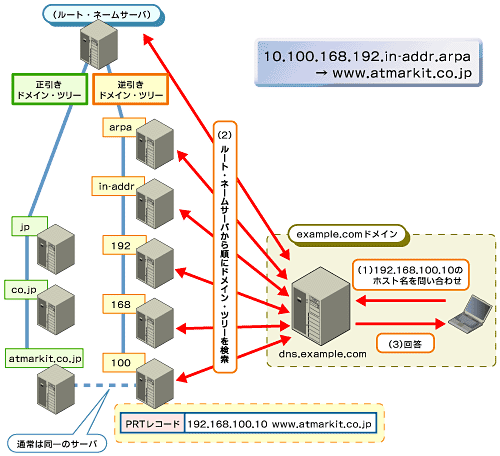 |
| 図5 逆引きレコードのDNS検索 |
考え方は完全に正引きと同じだ。ただし、トップ・レベル・ドメインとセカンド・レベル・ドメインは、「.in-addr.arpa」という特別な名前が付けられている。もちろん、それぞれのノードに該当するDNSサーバもちゃんと用意されている。ルート・ネーム・サーバは正引きと共通だ(一部提供しないルート・ネーム・サーバもあるようだ)。
ポイントは、それ以下のドメイン(ノード)部分で、検索の基になるIPアドレスを逆順に並べたものだ。つまり、IPアドレスの各オクテットを仮想的にノードと見なして、「第1オクテットを担当するDNSサーバ」→「第2オクテットを担当するDNSサーバ……」と順に検索を行う。このあたりの動作原理は、正引きのときと完全に同じだ。違うのは、DNSサーバが保持して管理しているデータの部分だけだ。
問題となるのは、このようなツリーを構築してDNSサーバで管理するためには、同じオクテットに属するIPアドレスをどの組織に割り当てるか、明確にして管理しなければならないという点だ。だが現在では、CIDR(Classless Inter-Domain Routing:クラス・レスな経路集積型ルーティング)のために、IANAなど、各ネットワーク管理機関が地域別にまとめて割り当てる管理が行われているため、普通は混乱することはない。
もっとも、組織内でプライベート・アドレスを基にDNS環境(独自のドメイン・ツリー)を構築する場合にも、CIDRを意識したIPアドレスの振り分けをしていないと、ルーティングだけでなく、DNS環境においても影響が出る可能性がある。複数のサブドメインを運用するならば、個々のサブドメイン内で使用するIPアドレスは、同一サブネットに属するアドレスをまとめて使用した方がいい。注意しよう。